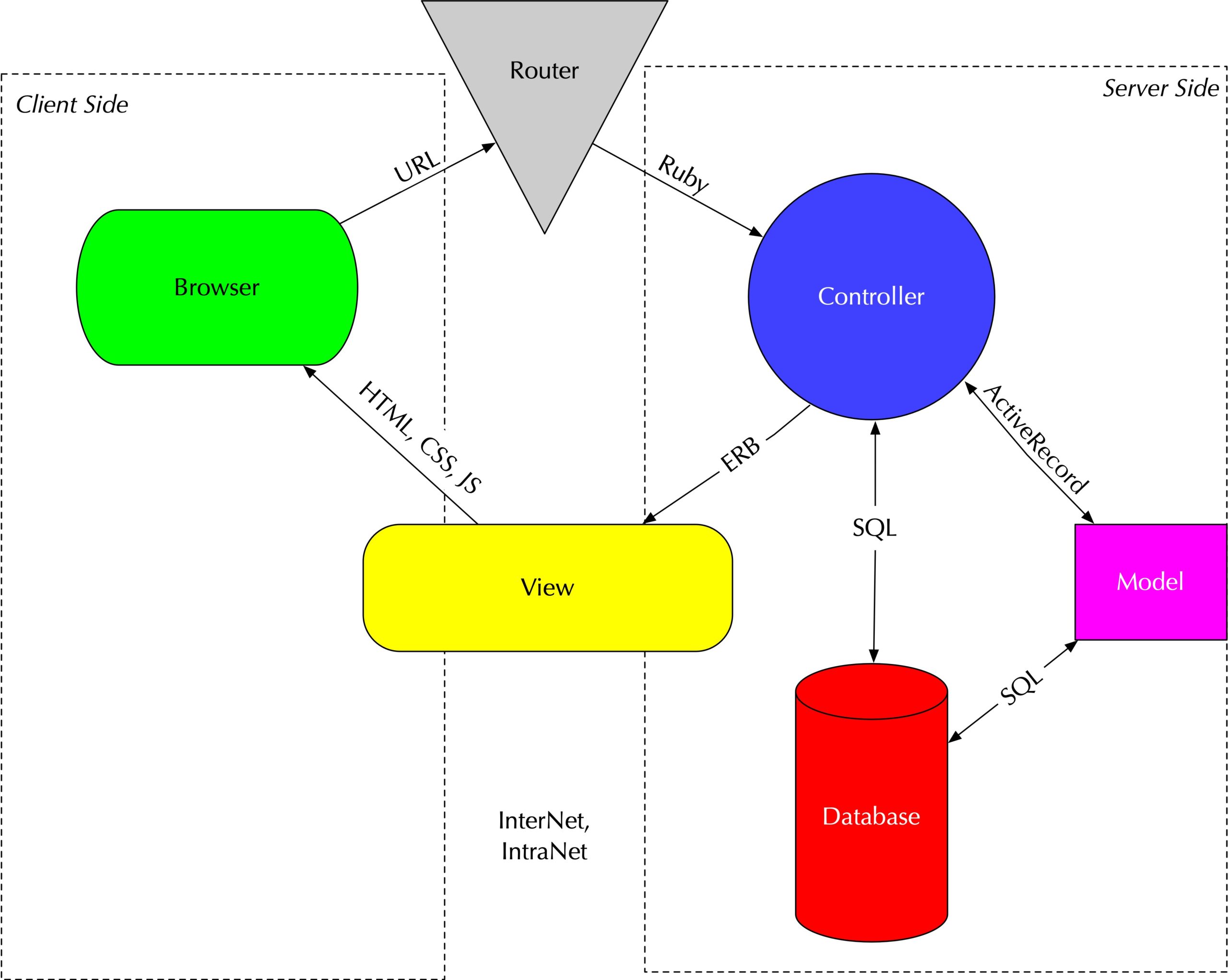
My talk last week at FOSSCon, “Debugging with PostgreSQL: A Strategic Approach” went well. Lots of energy in the room. Good audience.
Bruce Momjian, one of the founders of PostgreSQL, was in the audience & said afterwords (roughly): “that’s what I’ve been thinking for years; good to hear it spelled out in words”. I got that from a number of other programmers in the audience as well. Much pleased.
Bruce went on to ask I propose the talk for the 2020 World PostgreSQL Conference, which I shall.
I thought it might be helpful to write some of the code examples up in a complete script, so any one who wishes can run and/or hack. I found a few problems and infelicities myself while doing this. Further suggestions very welcome!
Warning: here there be code.
To run the code (assuming you have PostgreSQL 11 installed and call the sample “sample_all.sql”):
psql -U postgres -d postgres -f sample_all.sql > sample_all.out 2>&1
Since it can be tricky to cut-and-paste from a web page, I have uploaded the raw code as “sample_all.txt” (you can’t upload files with an SQL extension for security reasons). For completeness, here are the slides themselves as PDF.
The code is careful to create a sample database, build & test stuff, and then remove the whole thing as if nothing had happened. If you don’t like doing this sort of thing from the postgres user (don’t blame you) create a user with createdb privileges & use that to run this.
Sample Code
/*
John Ashmead
sample_all.sql: samples as used in my talk "Debugging with PostgreSQL"
FOSSCon 8/17/2019
Sample_all.sql is a complete code sample:
it builds a sample database called sample with a user sample
then creates a few types,
a timestamp trigger function,
a table people,
and then a small function to set the social security number
The goal was to provide illustrations for the talk of what I call "self-debugging code"
1) many problems are trapped, as by type checking, before they can do any harm
2) in other cases, you will get an exception
3) and in the worst case, at least you will see what went in and what came out
You can run this as user postgres database postgres. You could run as any user with createdb,
if you fix the clean section to go from "postgres" to that user.
I normally run scripts using psql with "-v ON_ERROR_STOP=1" set on the command line,
which will cause psql to exit on the first error.
But in this case you need to allow for errors in the test section.
Therefore an appropriate command line is:
"psql -U postgres -d postgres -f sample_all.sql > sample_all.out 2>&1"
The comments are taken from points made in the talk,
hence their perhaps slightly pedantic character.
Any comments, my email is "john.ashmead@ashmeadsoftware.com".
*/
\qecho Build user and database
create user sample with password 'HighlySecret';
create database sample with owner = sample;
\c sample sample
set search_path to public;
/*
Create generic timestamp function: timestamp_trg
Provided the tables use the fields "updated_at" and "created_at" as timestamps,
you do not need to rewrite this function on a per table basis.
It is very useful to have timestamp fields on most tables, even if they are not specifically needed:
1) knowing "when" something went wrong often takes you much of the way to figuring out "what" went wrong
2) and using triggers takes the load off the development programmer
I've been working a lot with Ruby-on-Rails which will create & update these fields for you.
But if you rely on Ruby-on-Rails then you create a lot of traffic on the wire,
and you can miss cases where the updates were done behind ruby's back,
as by other scripts & tools.
*/
\qecho Create timestamp function
create or replace function public.timestamp_trg() returns trigger
language plpgsql
AS $
begin
/* assume we have updated_at and created_at fields on the table */
if new.created_at is null
then
new.created_at = now();
end if;
new.updated_at = now();
return new;
end;
$;
/*
My own experience has been that it is much better to use logical types, even for simple fields:
1) it makes changing types much easier: if three tables are using a social security number,
then you only have to change it in one spot
2) it makes the field names almost self-documenting
3) and you can include bits of validation, as here, when the field is used
Obviously this, like any principle, can be carried to extremes.
This is, as Captain Barbossa might put it, a guideline rather than a rule.
*/
\qecho Create some types & then the people table
begin;
/*
Everysooften you run into someone with a single character last name, as Kafka's "K",
so we allow for that.
I prefer text to varchar or character. Performance about the same (in some cases better) and
if you put a fixed length in, what happens when you have to add the last name of a king or queen
where the name is basically the history of the monarchy?
*/
create domain public.lastname_t text check(length(value) > 0);
comment on domain public.lastname_t is 'holds last name. Has to be at least one character long.';
create domain public.firstname_t text;
comment on domain public.firstname_t is 'holds first name. Can be missing';
create domain public.middlename_t text;
comment on domain public.middlename_t is 'holds middle name or initial. Can be missing';
create domain public.ssn_t text check(value similar to '\d{9}');
comment on domain public.ssn_t is 'holds social security number. If present, must be 9 digits long.';
/*
ok_t is self-documenting in the sense that true is good and false is bad.
This seems obvious enough, but I have seen the reverse convention used.
As an aside, it is better for maintenance to use positive tests, i.e. "if we_are_ok"
rather than negative ones "if not we_are_failed". Slightly easier to read.
Which is important when it is 2am and the code has to be working by 9am.
Further, better to use "not null" whenever possible: three valued logic is a great source of bugs.
*/
create domain public.ok_t boolean not null;
comment on domain public.ok_t is 'true for success; false for successness challenged';
-- PostgreSQL sequences are a joy!
create sequence public.people_id_seq start 1;
/*
we are using the ruby convention that we should get the plurals right: person/people rather than person/persons.
The only place you see persons is in a police report:
three persons of a suspicious character were espied leaving the premises in a rushed and furtive manner.
*/
create table public.people (
id int primary key default nextval('people_id_seq'),
lastname lastname_t not null,
firstname firstname_t,
middlename middlename_t,
ssn ssn_t,
updated_at timestamp with time zone default now(),
created_at timestamp with time zone default now()
);
/*
In this simple case the comments are, in all candor, redundant.
But, if you comment everything, then tools like SchemaSpy can give you a nice report of everything in your database.
And, it is a good habit to get into.
*/
comment on table public.people is 'list of people';
comment on column public.people.id is 'primary key of people table';
comment on column public.people.lastname is 'lastname of person -- mandatory';
comment on column public.people.firstname is 'firstname of person -- optional';
comment on column public.people.middlename is 'middlename of person -- optional';
comment on column public.people.ssn is 'social security number of person -- optional';
comment on column public.people.updated_at is 'last time this row was updated';
comment on column public.people.created_at is 'time this row was created';
-- A unique index on id will be created automagically, so don't bother.
create index people_name_ix on public.people using btree(lastname, firstname, middlename);
create unique index people_ssn_uix on public.people using btree(ssn);
insert into public.people(lastname, firstname, middlename) values ('Programmer', 'J', 'Random');
select * from public.people order by id; -- make sure we look OK
/*
One useful trick is to put a begin at the top of a script & a rollback at the end,
until you are confident that the script works OK.
This can be done even for DDL -- i.e. create table -- an incredibly strong feature of PostgreSQL.
*/
-- rollback
commit;
-- create ssn_set
\qecho Create the social security function which served as the main example of self-documenting code
-- begin/commit not strictly needed, the create function is an atomic unit, but still a good habit
begin;
create or replace function public.ssn_set(
person_id0 public.people.id%type, -- makes certain the function & table types are lined up
ssn0 public.people.ssn%type, -- lets us get in a bit of validation (against the ssn type) before we get started
debug_flag0 boolean default false -- this lets you turn on debugging at will, if there is a production problem
)
returns ok_t as $
declare
person_id1 people.id%type; -- more specific than int
ssn1 people.ssn%type; -- could use ssn_t, but this is still more specific than a generic type
row_count1 bigint; -- more check-y stuff
begin
if debug_flag0 then
/*
notice the use of the function name in the message:
always identify the source in an error message! this could be part of a thousand messages
*/
raise notice 'ssn_set(%, %)', person_id0, ssn0;
end if;
select id into person_id1 from people where id = person_id0 limit 1; -- limit 1 is overkill
if person_id1 is null then
/*
be as specific as possible in an error message
*/
raise exception 'ssn_set: person_id0 % is not in people table', person_id0;
end if;
/*
We have a unique index on the ssn, but we can issue a more precise error message if we check first.
This also serves as a double-check if we set the table up incorrectly, unlikely for social security numbers,
but can happen in general.
*/
select id into person_id1 from people
where ssn = ssn0 and id != person_id0;
if person_id1 is not null then
raise exception 'ssn_set: ssn % is already in use by id %', ssn0, person_id1;
end if;
-- this whole function is really just an elaborate wrapper for this one line
update people set ssn = ssn0 where id = person_id0;
/*
and now make absolutely sure that it worked
*/
get diagnostics row_count1 = row_count;
if row_count1 != 1 then
raise exception 'ssn_set: unable to set ssn to % for person# %, rows affected = %', ssn0, person_id0, row_count1;
end if;
/*
giving the exit values as well as entry values of key variables lets us trace
the flow of gozintas and gozoutas without doing anything more than setting a debug flag
*/
if debug_flag0 then
raise notice 'ssn_set: person %: ssn changed to %', person_id0, ssn0;
end if;
/*
All previous returns were by "raise", this is our first "normal" return.
*/
return true;
end; $ language plpgsql;
commit;
/*
and of course the obligatory red/green tests
-- bracket the allowed value with three red tests, then verify it works
-- then check for dups: one red, one green
*/
\qecho Test the social security function: three red tests then one green
\qecho Expect fail -- nonsense
/*
We use the "(select...)" in the argument list to avoid hard-coding IDs,
this will make it easier to extend the tests further, if necessary.
I didn't bother to assign the "red" values into variables in this section,
since we are only using each value once.
*/
select public.ssn_set((select id from public.people where lastname = 'Programmer'), 'unmitigated nonsense'::ssn_t, true);
select * from public.people where lastname = 'Programmer';
\qecho Expect fail -- too short
select public.ssn_set((select id from public.people where lastname = 'Programmer'), '01234567'::ssn_t, true);
select * from public.people where lastname = 'Programmer';
\qecho Expect fail -- too long
select public.ssn_set((select id from public.people where lastname = 'Programmer'), '0123456789'::ssn_t, true);
select * from public.people where lastname = 'Programmer';
-- using variables with psql makes it easier to change up the tests later
\set test_ssn 012345678
\set test_ssn2 987654321
\qecho Expect success -- just right
select public.ssn_set((select id from public.people where lastname = 'Programmer'), :'test_ssn'::ssn_t, true);
select * from public.people where lastname = 'Programmer';
\qecho Second round of testing on the social security function: one red and one green
\qecho Expect fail: we have already used this SSN
insert into people(lastname) values ('Programmer Junior');
select public.ssn_set((select id from public.people where lastname = 'Programmer Junior'), :'test_ssn'::ssn_t, true);
select * from public.people where lastname = 'Programmer Junior';
\qecho Expect success: give Junior his/her own SSN
select public.ssn_set((select id from public.people where lastname = 'Programmer Junior'), :'test_ssn2'::ssn_t, true);
select * from public.people where lastname = 'Programmer Junior';
-- cleanup: you have to back out of the sample database and then remove first it, then the role
\qecho A clean database is a happy database
\c postgres postgres
drop database sample;
drop role sample;